- Auteur : Patrick
- Date d'envoi : le 8/4/2025 à 16:53:17
- Catégorie : Divers
- Niveau : Intermédiaire
- Version : Gambas 3 Se connecter
À propos de ce code
Bonjour
Les API sont des méthodes pour échanger des données avec des applications tierces, ces échanges se font essentiellement par données sous format Json ou par fichiers.
Le but du jeu est de pouvoir échanger n’importe quelle donnée de mon programme avec un programme tiers, ici l’accent est plutôt mis sur l’envoi de données.
Pour ce faire, on a plusieurs étapes :
- Une classe à copier dans vos programmes, API.class, celle-ci va vous permettre d’interpréter les fichiers xml et d’exécuter les requêtes, elle s’appellera comme ceci :
a= new API
retour as variant = a.exec(nomduscenario, var, result)
ou nomdusenario est une string contenant le « nom du scénario » à exécuter, c’est un fichier texte.
var est une collection contenant les noms et les valeurs de variables que vous voulez passer.
result est est les résultat d’une interrogation de base de donnée.
Retour[].tableau est une collection des variables
retour[].erreur est une string contenant un éventuel message d’erreur
retour[].json est une string contenant le fichier généré
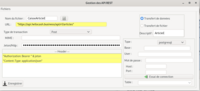
- Le premier écran va nous permettre de renseigner l’url, les entêtes (header), le jeton ou mdp et si on transfère un fichier ou des données avec le nom correspondant.
À noter que tout ce qui a un fond jaune est interprété avec Eval donc pour l’url par exemple on rentre : « mon url » & jeton ce qui sera interprété comme : mon url 124 !: …
Re à noter dans url et header si on met une chaine entre {} elle sera interprétée comme un fichier xml et sera remplacée par son équivalent Json :
« mon url {idsite} » ira chercher le fichier idsite,xml et renverra mon url{« name « : « patrick », « id » : « 1234 !:,,, »}
On aura aussi le type de transaction et le type MIME.
La partie base de donnée n’est qu’une aide à la saisie pour la partie suivante.
Il faut nommer ce fichier qui sera par défaut dans ~/,APIcontroler, c’est modifiable dans les paramètres. C’est un fichier xml avec une extension .Descriptif.
- Fichiers => Saisie des données
La partie gauche est un treetview qui récapituler ce que l’on va saisir sur la partie droite. Cette dernière va nous permettre de saisir le nom du champ de l’application tierce puis ce que l’on veut en faire : soit c’est un autre fichier xml qui va se comporter comme un tableau, soit un champ calculé tous les champs de l’application tierce sont des variables utilisables ici et dans le 1° écran, soit un champ de la base de donné.
En dessous on a le type de donnée et son éventuel format.
Si on coche « champ à conserver en variable » elle sera conservée pour la prochaine requête du scénario,
Si on coche « À répéter autant de fois qu’il y a de résultat » on crée un tableau.
- Il nous reste a créé le scénario qui va être une liste de descriptif qui vont s’exécuter l’un après l’autre. Un exemple de scénario, j’ai créé une liste d’enregistrement dans un programme tiers, je veux en modifier un. La règle du programme tiers est que :
* Lors de la création d’un enregistrement il lui est attribué un identifiant unique
* Pour modifier un enregistrement j’ai besoin de cet identifiant
* Si l’identifiant est null un nouvel enregistrement sera créé
* Il est mis à ma disposition des filtres pour lire un enregistrement
Dans le scénario je vais donc pouvoir exécuter une requête qui va lire l’enregistrement que je veux puis marquer l’identifiant comme à conserver puis exécuter une autre requête qui va écrire les modifications avec le bon identifiant.
L’utilité de ce programme pour moi est de pouvoir sur Laurux :
- Poster les factures sur les futures plateformes PDP (facturation électronique)
- Poster les factures sur Chorus Pro (administration)
- Poster les écritures comptables sur le logiciel de mon expert-comptable pour avoir une compta en temps réel et moins de re saisie et donc moins de risque d’erreurs, je ne sais pas si je vais y arriver leur prestataire n’est pas très « open ».
- Et qui n’est plus d’actualité, tenir à jour des articles sur une caisse enregistreuse.
J’espère ne pas avoir été trop confus dans mes explications.
Patrick
Commentaires
Introduction :
Les termes « API » ou « Interface de Programmation d’Applications » sont devenus courants. Mais qu’est-ce exactement qu’une API et pourquoi est-elle si cruciale pour le fonctionnement de nombreux services et applications que nous utilisons quotidiennement ?
Explication générale :
API est l’acronyme de « Application Programming Interface » ou en français, Interface de Programmation Applicative. En termes simples, c’est un ensemble de règles et de spécifications qui permettent à différentes applications logicielles de communiquer entre elles. Imaginez une API comme un interprète qui facilite la communication entre deux personnes parlant des langues différentes.
Explication métaphorique :
Pensez à une API comme à une prise électrique universelle lors de vos voyages à l’étranger. Au lieu d’apporter une multitude d’adaptateurs pour chaque pays, vous utilisez simplement un adaptateur universel qui se connecte partout. De la même manière, une API offre une norme universelle pour que différents logiciels et applications puissent se connecter et interagir les uns avec les autres sans complications.
Exemple d’utilisation :
Lorsque vous naviguez sur un site web ou une application et que vous voyez l’option « Se connecter avec Google« , ça signifie que ce site utilise l’API de Google pour faciliter cette connexion. Au lieu de vous créer un nouvel identifiant et un nouveau mot de passe, vous pouvez simplement autoriser le site à accéder à certaines informations de votre compte Google. Ça simplifie grandement le processus d’inscription, rendant votre expérience en ligne plus agréable et rapide.
Dans ce cas précis, Google a créé une API permettant de récupérer les identifiants de connexion (adresse e-mail et mot de passe) d’un compte utilisateur pour que vous puissiez vous connecter sur un autre site avec vos identifiants Google. Cette API permet à un développeur d’intégrer ces identifiants dans son application. Ainsi, les utilisateurs ont la possibilité d’utiliser leurs identifiants Google au lieu de créer un nouveau compte, ce qui peut être rébarbatif de se créer un compte pour tout.
Lorsqu’un développeur souhaite intégrer une fonctionnalité d’une application dans son application, il peut utiliser l’API fournie par cette application. Il n’a pas besoin de connaître tous les détails internes de l’application source, il se contente d’utiliser les fonctions disponibles via l’API pour interagir avec elle de manière standardisée.
Lorsque vous développez une application et que vous souhaitez intégrer des fonctionnalités d’une autre application ou d’un service, vous pouvez utiliser une API si elle est proposée par le fournisseur du service.
Voici comment ça fonctionne généralement :
Documentation de l’API:
Avant tout, le fournisseur du service doit fournir une documentation détaillée sur son API. Cette documentation décrit comment interagir avec l’API, quelles sont les requêtes disponibles, comment formater les données d’entrée et comment comprendre les réponses.
Intégration de l’API dans votre application: Une fois que vous avez compris comment fonctionne l’API grâce à sa documentation, vous pouvez l’intégrer dans votre application. Ça implique généralement d’envoyer des requêtes HTTP (comme GET, POST, PUT, DELETE) à l’API, de traiter les réponses et d’afficher les données à vos utilisateurs.
Authentification:
Dans de nombreux cas, vous devrez vous authentifier auprès de l’API pour pouvoir y accéder. Ça peut se faire via des clés API, des jetons d’accès ou d’autres méthodes d’authentification.
Gestion des erreurs: Il est important de gérer les erreurs qui peuvent survenir lors de l’utilisation d’une API. Ça peut inclure des erreurs réseau, des erreurs de validation, ou des erreurs spécifiques à l’API.
Mises à jour de l’API: Les API évoluent avec le temps. Il est donc essentiel de surveiller les mises à jour et de mettre à jour votre intégration en conséquence.
Limitations et tarification:
Certaines API ont des limitations d’utilisation (comme un nombre maximum de requêtes par minute) et peuvent être soumises à des frais. Assurez-vous de bien comprendre ces limitations pour éviter les problèmes potentiels.